1. 인공지능을 개발할 때 소요되는 시간
인공지능을 개발할 때 가장 많은 시간을 필요로 하는 것은 데이터이다. 전체의 80%를 차지하고 있다.

한 분야의 인공지능을 개발하기 위해서는 필요한 데이터가 어떤 종류의 것이어야 하는지를 분석하는 식별 작업을 거치다. 이렇게 정의 내려진 데이터를 수집하고, 수집된 데이터를 필요에 맞게 가공, 분류하는 작업을 거친 후 데이터 라벨링 작업에 들어간다. 데이터 라벨링은 기계가 데이터를 이해할 수 있는 상태로 작업하는 것이다. 테이터 증강은 부족한 부분의 보완과 잘못된 부분의 수정을 말한다.
AI 알고리즘부터 배포까지는 전문가들의 영역이지만 수집부터 증강까지는 비전문가들도 참여할 수 있는 분야이다. 아무리 뛰어난 AI 알고리즘을 개발하다고 해도 처리할 데이터가 없으면 AI는 아무 쓸모가 없다. 때문에 인공지능 개발에는 많은 인력을 필요로 한다. 더욱이 모든 산업 분야에서 인공지능을 필요로 하기 때문에 '데이터 라벨링' 작업에 필요한 인력은 더 많아질 것으로 예상된다.
하지만 준비되지 않은 사람이 참여하는데 한계가 있다. 지금부터라도 공부하고 관련된 자격증을 따놓으면 크게 소용될 것이다.
2. 테이터 라벨링이란
인공지능에서 사용하는 데이터를 가공하는 형식이 데이터 라벨링이다.
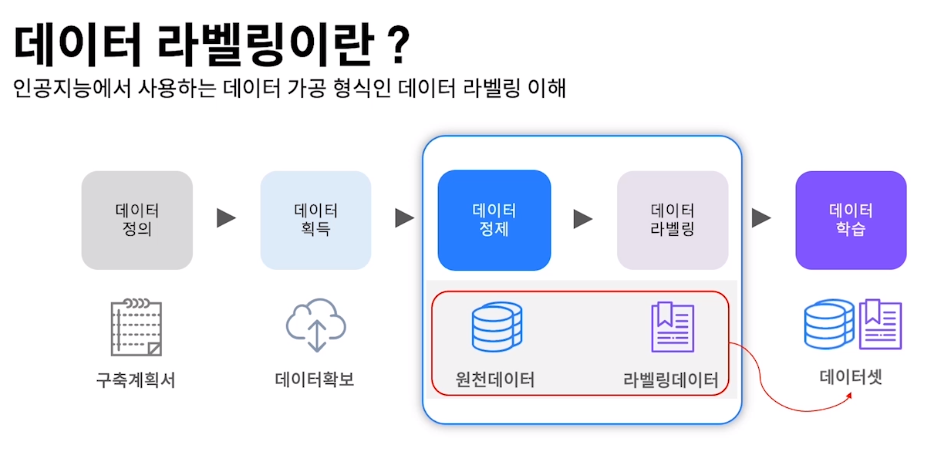
데이터 정의
각 인공지능 개발에는 개발의 목적이 명확하다. 그 목적에 맞는 데이터가 무엇인지 정의하는 것으로 인공지능의 개발이 시작된다. 다
데이터 획득
음으로 정의 내려진 데이터를 확보하는 작업이 필요하다. 이때 필요한 양은 매우 방대한 양이될 것이다.
데이터 정제
데이터를 수집하고 가공과 분류 작업을 거쳐 표준화하는 작업을 '데이터 정제'라고 한다.
데이터 라벨링
이렇게 정제된 데이터를 기계가 이해할 수 있는 형태로 가공하는 작업이 '데이터 라벨링'이다.
빅데이터
1. 빅데이터란

빅데이터란 대량의 모든 데이터와 데이터의 가치와 결과분석 기술, 빅데이터 플랫폼, 관리 기술을 포함하는 개념이다.
2. 데이터 발생 량(2015년 기준 1분간 전 세계 데이터 발생량)

단 1분 만에 발생되는 데이터의 량이다. 이 외에서 전 세계의 수많은 사이트에서 발생되는 양까지 합치면, 그 방대한 양은 짐작하기조차 어렵다
3. 시대에 따른 데이터의 변화

2000년대 들어 발생되는 데이터의 양이 급격히 증가하였다. 그 이유는 SNS의 발달과 스마트폰 발명에 있다. 2000년대 들어 SNS를 통해 개개인이 데이터를 발생하는 주체가 되었고, 스마트폰이 나온 뒤로 사람들은 시간과 장소에 구애받지 않고 데이터를 생산하게 되었다.
2020년 들어 메타버스가 활성화됨에 따라 데이터의 생산과 사용은 새로운 변화를 맞기 시작했다. 데이터의 생성과 사용이 다른 방향으로 흘러가기 시작한 것이다.
'데이터라벨링' 카테고리의 다른 글
| 데이터 라벨링, Welocalize 소개 (0) | 2023.01.14 |
|---|---|
| 데이터 라벨링 웹사이트, LabelOn 소개 (0) | 2023.01.13 |
| 데이터 라벨링으로 월 300 벌기, 3강 인공지능 알고리즘 (0) | 2022.12.31 |
| 데이터 라벨링의 개념 이해하면 월 900만원도 가능 (0) | 2022.12.29 |
| 데이터 라벨링 시작하기 (0) | 2022.12.29 |